

Empathy
Thema eines Kurses im Wintersemester 21/22 an der Hochschule Mainz war die Auseinandersetzung mit Datensätzen, durch die künstliche Intelligenzen trainiert werden können. Häufig handelt es sich dabei um riesige Datenmengen, die nur schwer zu begreifen sind. Die Aufgabe bestand darin, einen spannenden Datensatz zu finden und einen Weg zu gestalten, diesen begreifbar zu machen.
Konzept
Ich habe mich mit dem Datensatz COVID-19-TweetIDs beschäftigt, welcher im Rahmen des Papers Tracking Social Media Discourse About the COVID-19 Pandemic: Development of a Public Coronavirus Twitter Data Set veröffentlicht wurde. Zum Zeitpunkt der Veröffentlichung umfasste der Datensatz ungefähr 72 Millionen Tweet-IDs. Der Datensatz wird allerdings konstant mit neuen Tweets erweitert. Dadurch umfasst er mittlerweile eine Menge von mehr als 2 Milliarden Tweet-IDs (Zeitpunkt: 17.03.2022).
Um diese riesige Menge an Daten zugänglich zu machen, wollte ich ein Web-Interface entwickeln. Über dieses Web-Interface soll der Datensatz erforscht und über diverse Interface-Elemente gefiltert werden können.
Außerdem hatte ich die Idee, die Tweets aus dem Datensatz über eine KI in Emotionen einordnen zu lassen. Das hat einerseits den Vorteil, dass der Datensatz vorsortiert wird und dadurch der User einen leichteren Zugang erhält. Zusätzlich schafft man dadurch auch ein Verständnis für den emotionalen Zustand der Gesellschaft im Verlauf der Pandemie. Das fand ich spannend, da ich das Gefühl habe, dass im Zuge der Pandemie viel über klare Zahlen, wie zum Beispiel der Inzidenz, Hospitalisierungsrate oder der Todesrate diskutiert wurde, weniger aber darüber, wie sich die Menschen gefühlt haben.
Interface-Gestaltung
Das Interface lebt stark von der organischen Grafik in der Mitte. Diese Grafik besteht aus sieben Clustern, bei der jeder Cluster für eine von sieben Emotionen steht. Die sieben Emotionen sind joy, confident, anger, fear, tentative, analytical und sadness. In die Grafik kann hinein und herausgezoomt werden, um die einzelnen Cluster zu betrachten. Wenn man sich einem Cluster nähert, erkennt man, dass dieser mit Kreisen gefüllt ist, wobei jeder Kreis einem Tweet entspricht.
Außerdem verändert sich die Grafik, abhängig von der Einstellung der Zeitleiste auf der linken Seite. Sprich, wenn die Zeitleiste auf den Beginn der Pandemie eingestellt ist, sieht die Grafik anders aus, als wenn die Zeitleiste auf den mittleren Verlauf der Pandemie eingestellt ist. Dadurch wird es möglich, nachzuvollziehen, wie der emotionale Zustand der Gesellschaft zu unterschiedlichen Zeitpunkten im Verlauf der Pandemie war.
Jeder Emotion wurde außerdem einer Farbe zugeordnet, um die Einordnung der Emotionen visuell stärker hervorzuheben. Welche Farbe welcher Emotion entspricht, sieht man in der Legende unten rechts im Interface. Über die Legende kann man zudem einzelne Emotionen an- und ausschalten.
Neben der Möglichkeit, die Tweets über die Grafik zu erkunden, kann man auch über den Button am unteren Bildschirmrand direkt in eine Listenansicht springen. Diese Listenansicht bietet eine chronologische Ansicht der Tweets, in der man Tweets geordneter betrachten kann. Innerhalb dieser Liste werden auch einschneidende Events im Verlauf der Pandemie aufgezeigt, um den emotionalen Zustand in einen zeitlichen Kontext zu setzen.
Als Schrift kommt die Fracktif vom Studio Degarism zum Einsatz.
Technische Umsetzung
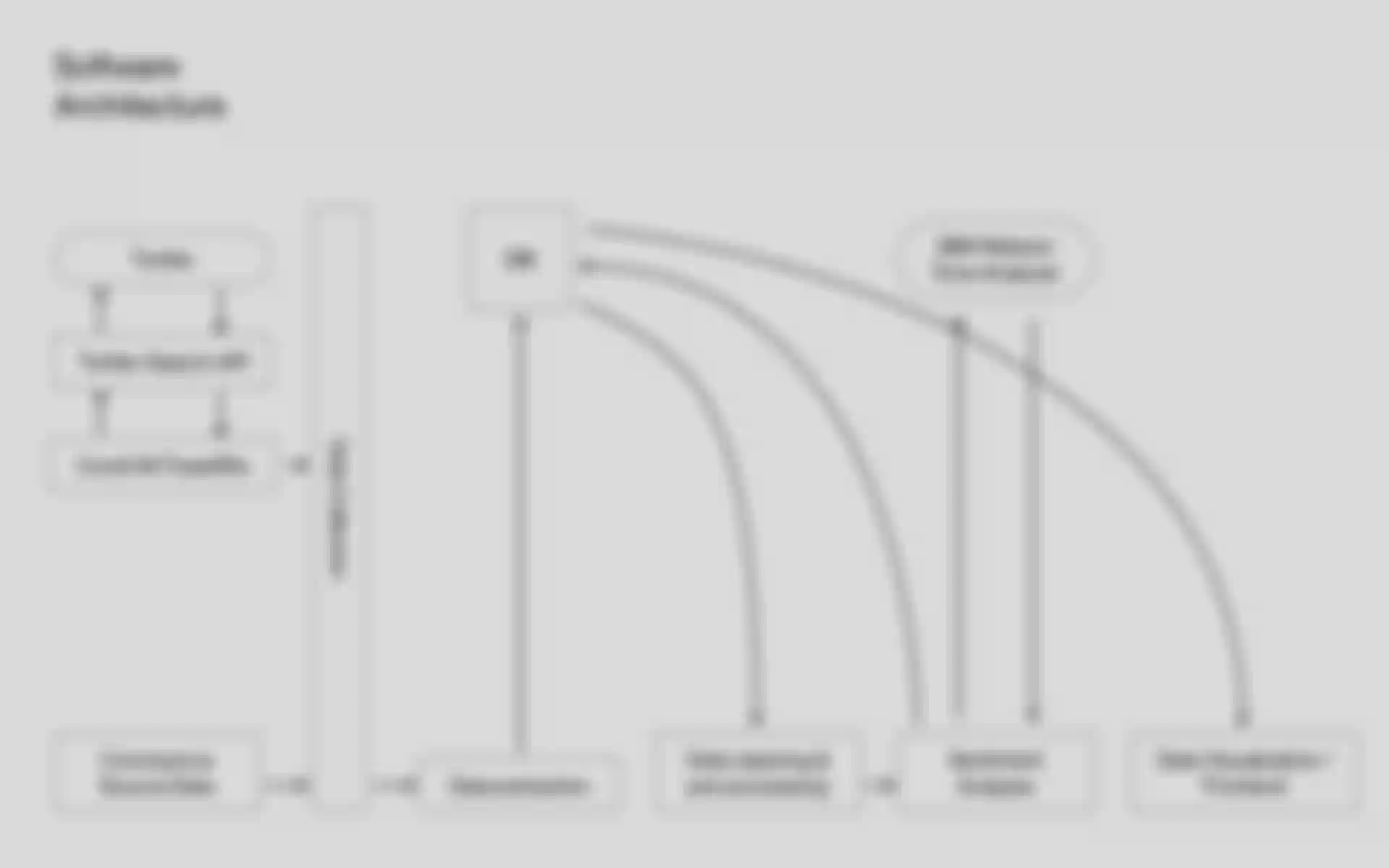
Um die Darstellung der Daten im Web zu ermöglichen, müssen zunächst einige Schritte unternommen werden, in denen die Daten aufbereitet werden. Im ersten Schritt werden alle nötigen Daten gesammelt. Das sind in meinem Fall die Tweets, als auch die Corona-Fallzahlen. Um die einzelnen Tweets zu erhalten, wird die Twitter API mit den Tweets-IDs aus dem Datensatz angesprochen und die Antwort der API abgespeichert. Die Corona-Fallzahlen werden aus dem Coronavirus Source Data-Datensatz der John-Hopkins-Universität bezogen. In einem weiteren Schritt werden dann relevante Daten aus den API-Antworten als auch aus dem Coronavirus Source Data-Datensatz extrahiert und in einer MongoDB-Datenbank abgelegt.
Danach werden die Tweets an die API des IBM Watson Tone Analyzer geschickt, um eine Sentiment Analysis zu erhalten. Dadurch werden die Tweets in eine der sieben oben genannten Emotionen eingeordnet. Sollte ein Tweet zwei oder mehreren Emotionen zugeordnet werden, wird die Emotion mit dem höchsten Wert ausgewählt. Die Emotion wird dann zum passenden Tweet in der Datenbank gespeichert.
Nach der erfolgreichen Datenaufbereitung können die Daten in einem Frontend entsprechend der vorangegangenen Gestaltung aufbereitet werden.
Ausblick
Leider hat es das Projekt noch nicht über den Prototypen-Status hinausgeschafft. Einige der Daten habe ich aber bereits aufbereitet und ich plane damit in Zukunft dieses Tool noch umzusetzen. Es wird hier ein Update geben, sobald es so weit ist. 😉