Francesco
Scheffczyk

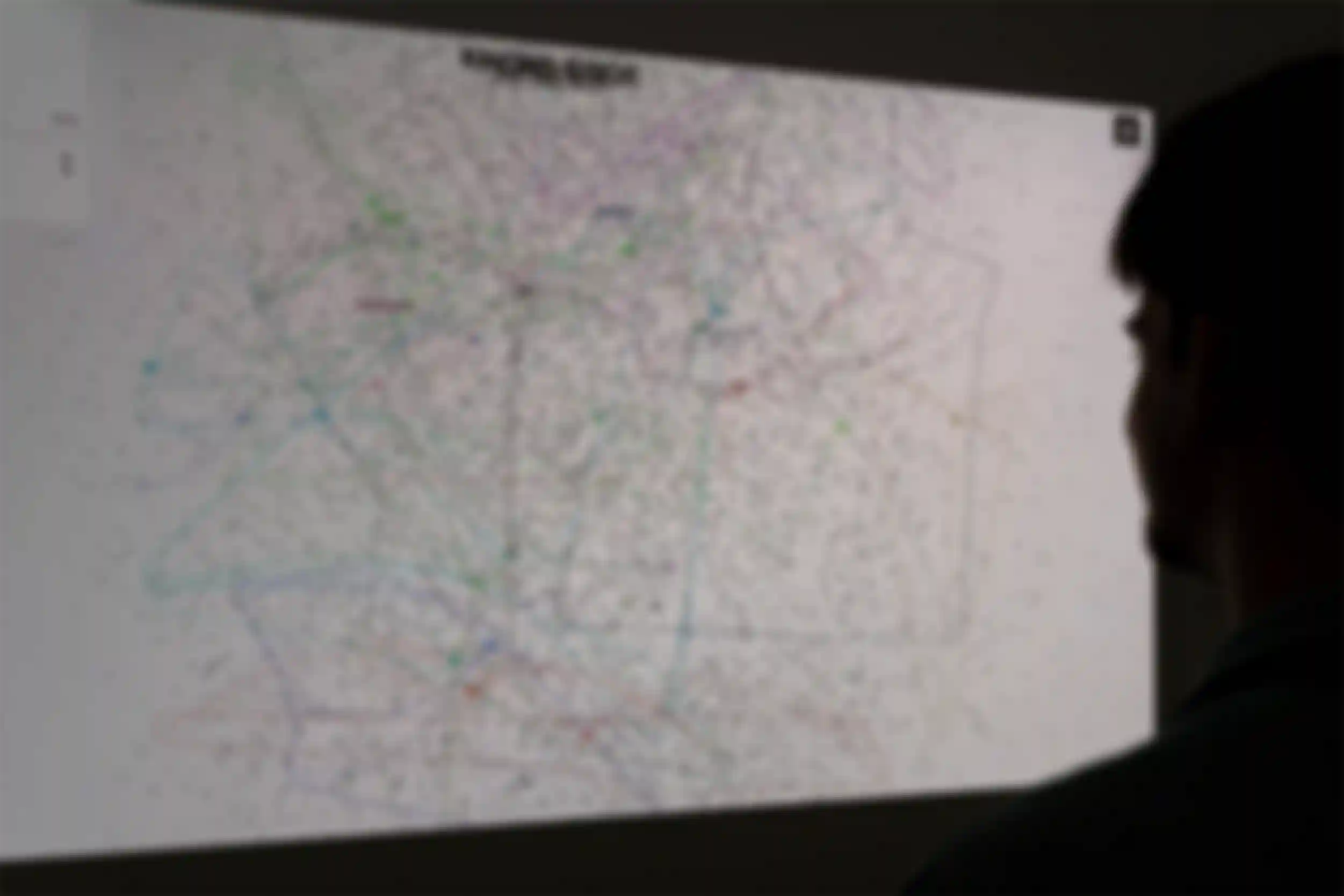



knowledge spaces
Recent developments in AI in 2022 and 2023 have led to many newly released tools based on large language models, such as ChatGPT, Bing Chat or Bard. While these tools and the underlying AI models are impressive, it has become increasingly clear that they don't know everything. This raises the following questions:
What is the true extent of an artificial intelligence's knowledge?
What does a latent space look like, and how can it be made more accessible and explorable?
The aim of knowledge spaces is to explore new ways of visualising and exploring the latent spaces of AI models and making them more accessible and engaging for the public.
Research
A latent space is a mathematical space that is used in machine learning to represent a large dataset in a lower-dimensional space. A latent space is created by training an AI model on a dataset. This latent space represents the "knowledge" of an AI model. Although the latent space is a lower dimensional space than the dataset, itis still a difficult task to visualise. Humans can only perceive up to three dimensions, while latent spaces typically consist of more mathematical dimensions.
Due to the difficulty of visualising latent spaces, this case is widely studied in the scientific and artistic community. Some projects and resources that have been used as references are:
- Atlas by Nomic AI
- Visualizing High-Dimensional Space by Daniel Smilkov, Fernanda Viégas, Martin Wattenberg and the Big Picture team at Google
- Latent Space Cartography: Visual Analysis of Vector Space Embeddings by Yang Liu, Eunice Jun, Qisheng Li and Jeffrey Heer
Based on the referenced sources and an exploratory phase, in which a number of approaches were tested, the following concept emerged. An extensive collection of additional sources can be found at ✨ are.na.
Concept
To make the knowledge of large language models accessible, a web interface has been created that provides users with an interactive platform to explore and search high-dimensional vector embeddings, visualised on a two-dimensional surface. Each high-dimensional vector embedding is represented as a cross on the surface, and each search generates a new cross, drawing connections between similar pieces of data in the embedding space. The resulting network of interconnected information will create visually appealing network structures, following recent studies suggesting that knowledge is best represented as rich, interconnected networks rather than linear trees.
The visual inspiration comes from Mark Lombardi's Narrative Structures.

“World Finance Corporation and Associates, c. 1970-84: Miami, Ajman, and Bogota-Caracas (Brigada 2506: Cuban Anti-Castro Bay of Pigs Veteran) (7th Version),” 1999, Color pencil and graphite on paper, 69.125 x 84 inches.
By allowing the users to create their own networks, they can explore the dataset on their own terms and develop a deeper understanding of the dataset and the AI models being trained on it. These networks will also be stored in an archive, allowing users to revisit their previous explorations of the knowledge space.
By making this project available on the web and creating an intuitive, user-friendly experience, knowledge about datasets and AI will become more accessible and explorable to a wider audience. In addition, the website will be complemented by explanatory texts that explain and demystify latent spaces and the knowledge embedded in AI models.
Implementation
In order to be able to search datasets that represent the "knowledge" of an AI model, they had to be processed in a certain way. The first processing step was to transform words or text units, also known as tokens, into multi-dimensional mathematical vectors.
Since it is impossible for humans to perceive more than tree dimensions, the vectors were processed in a second step to reduce their information density. This allowed the vector to be stored as a two-dimensional vector, which in turn allowed it to be visualised on a two-dimensional surface.
The datasets were processed using the SentenceTransformers library. After processing the datasets, they were pushed to Huggingface for storage and versioning using the 🤗 Datasets library.
The embedded datasets are served by a custom API built using FastAPI. This API also provides an endpoint for interfering with the LLM to find the nearest neighbour to a query. This data is then visualised as networks in a SvelteKit frontend available at https://knowledge-spaces.com. Both the data points and the searches are visualised using an HTML canvas implemented using the Konva.js library.
Have a look at the README in the GitHub repository for a deeper understanding of the technical implementation.
The archive feature, as well as the explanatory text mentioned above, is still under development.
Exhibitions
2024: Studies of Change – Transformative dialouges between art, design and technology, Bremen, Germany
2023: Transform 2023, Hochschule Trier, Trier, Germany
This project was realised in the courses "Complex Complex" and "Expanded Material Imaginaries" by Ralf Baecker during the winter semester 22/23 and summer semester 23.